
博客之前一直用的随机图api,虽然省心,但是加载慢,而且加载的角色都不认识。发现绳网情报站有绝区零所有角色的影画,所以写个爬虫全都抓下来当封面用。中间遇到好多新技巧,记录一下。
分析来源
https://baike.mihoyo.com/zzz/wiki/
先分析页面,打开影画页面,复制影画展示3的图片url,发现是这样的:
1 | https://act-upload.mihoyo.com/nap-obc-indep/2024/11/06/76099754/93171af7d069601a30c8129ebbfaff34_7755247229681328322.png?x-oss-process=image/format,webp |
下载下来是webp,如果把get参数全部去掉下载的就是png
然后去找这个图片的url是哪来的
复制一部分图片名称直接在burp里查找,找到有图片url的响应包。
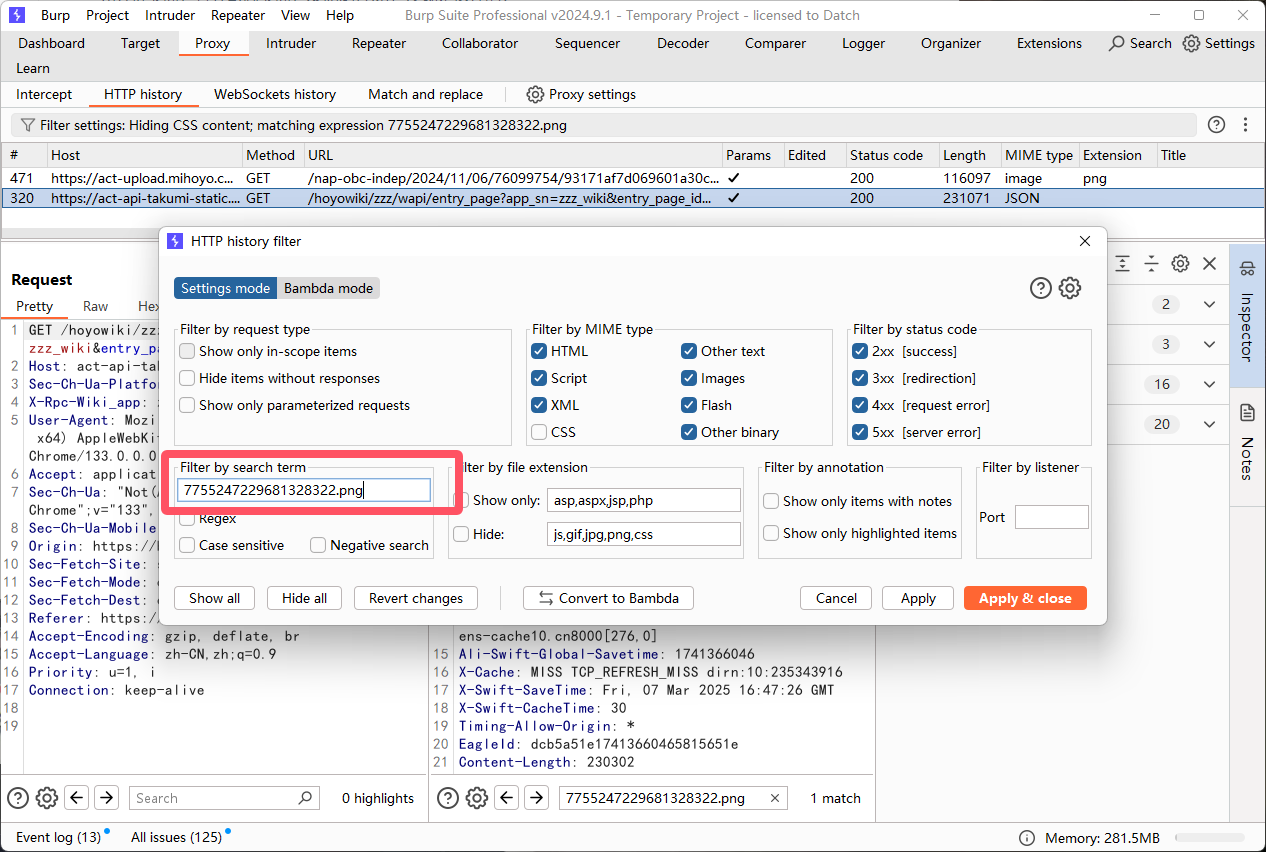
技巧一,burp响应包筛选
正常情况下直接像上图一样搜索就行了,但是这样会把请求里有
7755247229681328322.png的也筛选出来,如果想只筛选响应中有的,可以用Bambda mode。点一下
Convert to Bambda把当前的设置转为代码的格式,此时出现的是burp插件的montoya api写的代码
requestResponse是请求和响应的组合,它有一个response方法可以获取到响应,所以直接改成如下格式就好
2
&& requestResponse.response().contains("7755247229681328322.png", false);这样就只筛选响应包了
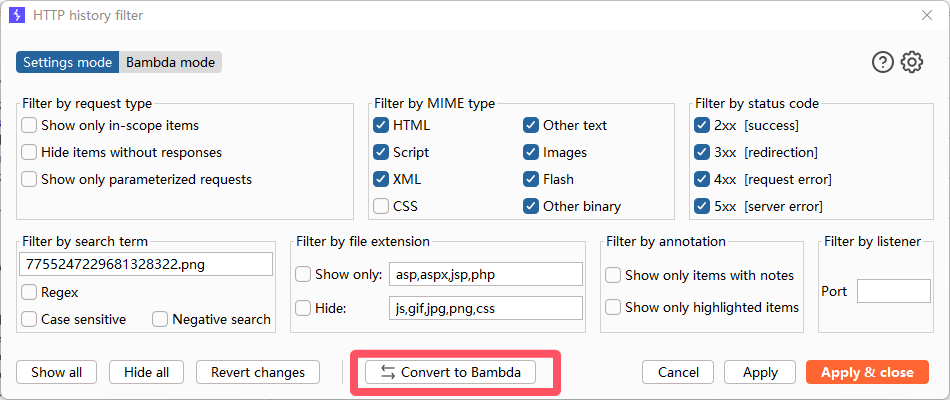
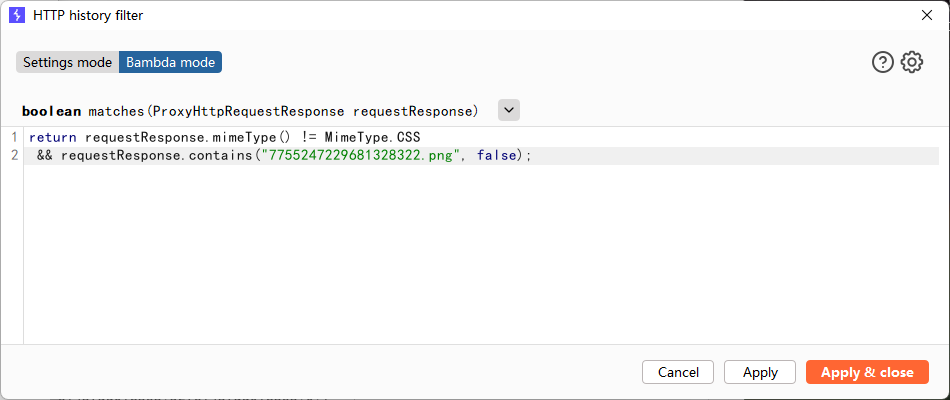
找到这个包之后,发现这个包的请求里有个参数entry_page_id=916,这个就是标识wiki页的 id。怎么确定的,因为浏览器当前页面的url里也有这个id,而且整个请求包里找不到其他可能做索引的参数了。
响应包里除了影画3,影画1和2的url也都有
现在,只要获取到所有角色的entry_page_id,就可以爬取到所有角色的影画了
在所有角色的目录页,可以找到每个角色详情页的跳转url,其中就有id
获取所有id
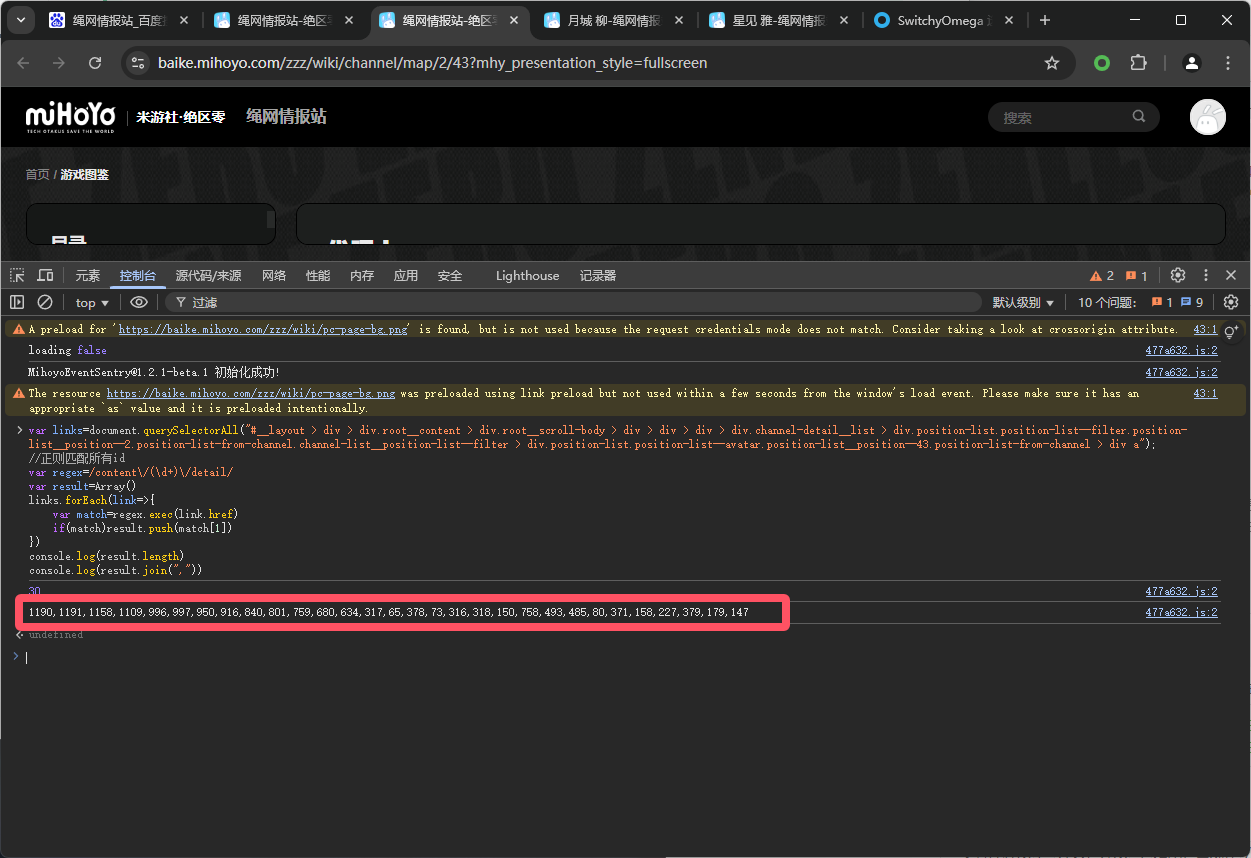
技巧二,快速定位dom节点
右键包含所有角色的最小div标签,复制JS路径
在CSS选择器最后加一个a就是选择这个div元素下所有的a标签
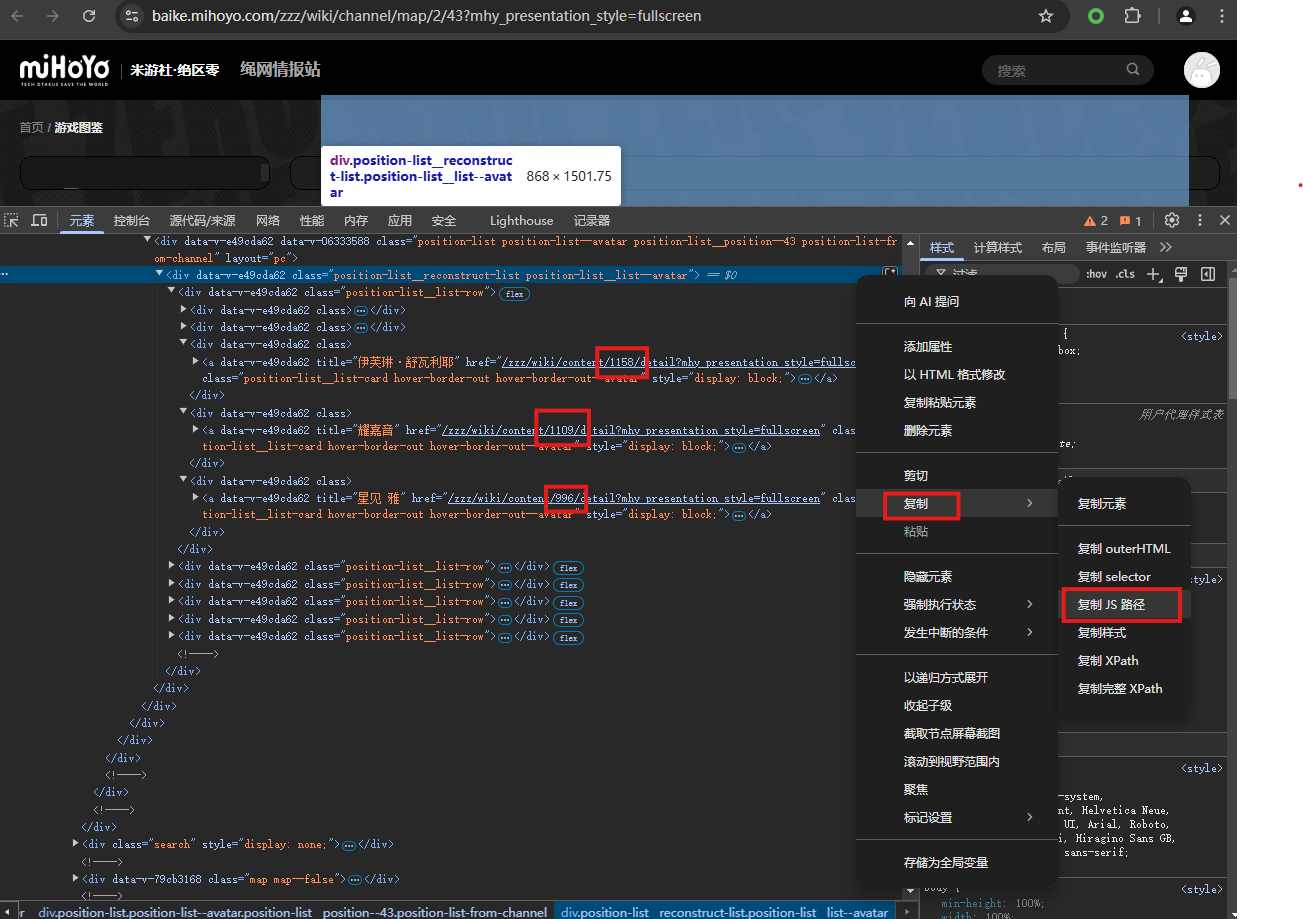
此时可以写js代码来获取所有id:
1 | var links=document.querySelectorAll("#__layout > div > div.root__content > div.root__scroll-body > div > div > div > div.channel-detail__list > div.position-list.position-list--filter.position-list__position--2.position-list-from-channel.channel-list__position-list--filter > div.position-list.position-list--avatar.position-list__position--43.position-list-from-channel > div a"); |
获取影画链接下载影画
有了id,就可以写脚本了
当时写的时候没有零号·安比和波可娜,这两个是前瞻没有影画图。把这两个的id去掉,即1190和1191
1 | import json |
写脚本的时候出现了一个问题,返回的包不是绝区零的数据,而是原神的。看了下请求包里有个请求头比较可疑:X-Rpc-Wiki_app: zzz加上请求头就是绝区零的数据了
urlretrieve是urllib.request里的函数,用于从url下载文件,第一个参数是url,第二个参数是存储的路径。urllib比requests更底层,没必要用requests获取数据后读响应体再写到文件里。
然后是从包里查找url,由于返回的json很大,转成字典后再一个键一个键的去索引很麻烦,所以直接用正则匹配了。中间到柏妮思的时候出现了问题,包里的image和tab_name顺序变了(json的对象{"key1":"value1","key1":"value1"}是无序的,出现这种情况很正常)。好在只有两个键值对,再写一个反过来的正则就可以了。
但是,这一步有更好的办法定位json元素
技巧三,快速获取json元素
把响应的json复制到一个json文件里,用pycharm打开,找到影画那里的key,右键,
复制/粘贴特殊>复制引用此时,就获取到了这个元素的路径:
data.page.modules[7].components[0].data直接
json.loads返回的是字典,不支持这样调用,但是可以添加参数object_hook=lambda d: SimpleNamespace(**d)返回一个对象,这样就支持以对象属性的方式调用了。原理就是object_hook是每解析出json的一个对象并返回时调用,我们可以不让他返回字典,而是用SimpleNamespace构造一个对象返回。**d是解包,把d拆开传参,d是字典(因为是object_hook,json的object对应py的字典)就相当于SimpleNamespace(k1=v1,k2=v2)。SimpleNamespace就是一个对象,传什么就有什么属性。所以这里就可以很方便的获取到url所在元素的位置,里面还是个json,但这个json很小,直接字典索引就行
改过之后的脚本:
1 | import json |
除此之外,也可以复制json pointer,用json pointer来快速获取json元素,但是这个要装第三方库。不如object_hook普遍。